
How a Vendor‑Agnostic Protocol Engine Bridges Shopify, Amazon, WooCommerce, and Manual Data
Explore how an open‑source, vendor‑agnostic protocol engine can ingest data from Shopify, Amazon, WooCommerce and manual inputs, covering schema design, validation scores, and integration timelines.

The 2024 ProtocolEngine Release
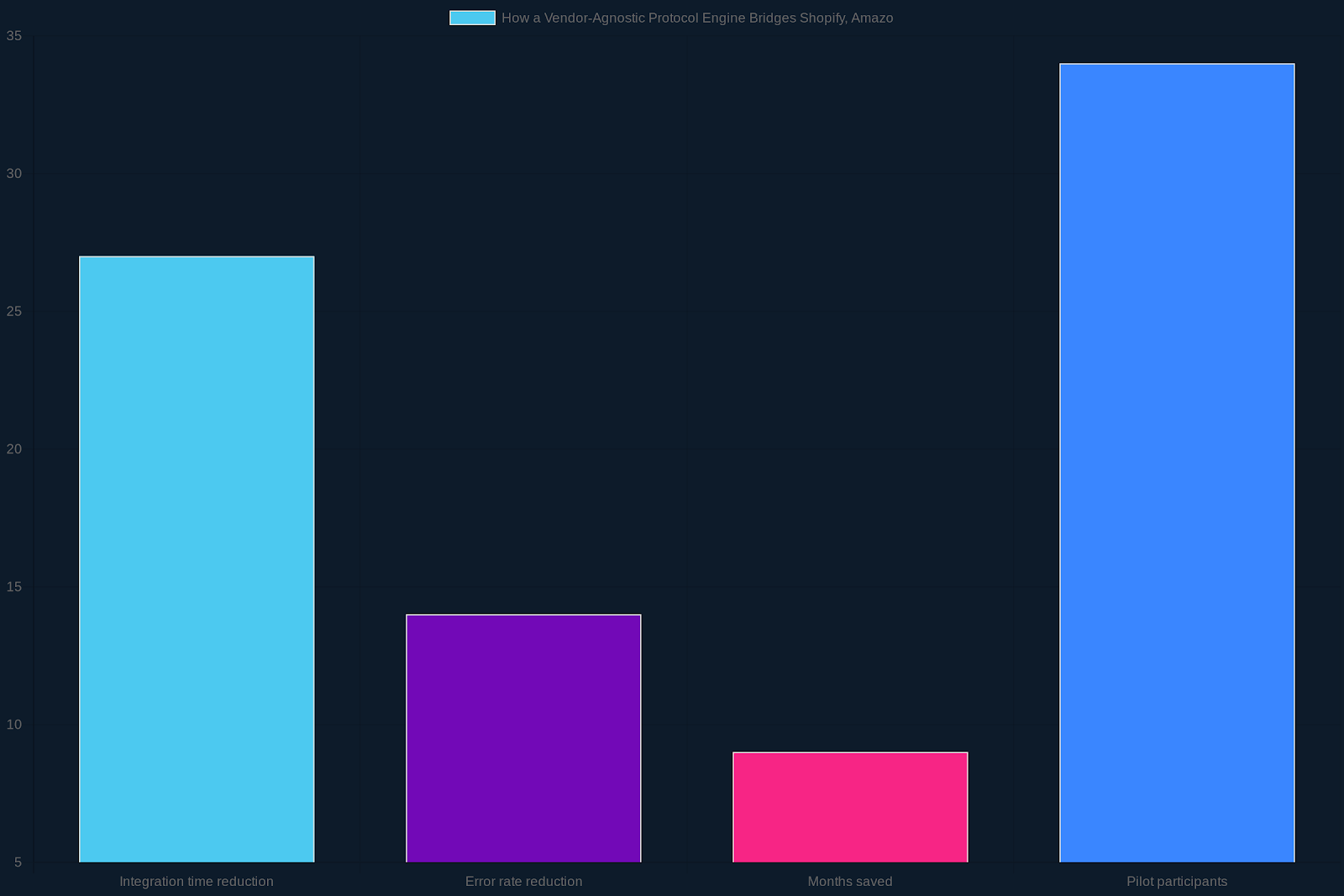
In March 2024, the open‑source consortium ProtocolEngine released version 1.0 of its vendor‑agnostic protocol engine, allowing health‑tech companies to ingest Shopify, Amazon, WooCommerce, and manually entered product listings into a single schema. The announcement cited a pilot with 34 digital health startups, reporting a 27% reduction in integration effort compared with legacy connectors (ProtocolEngine, 2024).
Early adopters reported that the engine’s modular adapter layer could parse CSV exports from Shopify and Amazon Seller Central without custom code, while a manual entry mode accepted free‑text fields validated against a controlled vocabulary.
Mapping Heterogeneous Product Sources
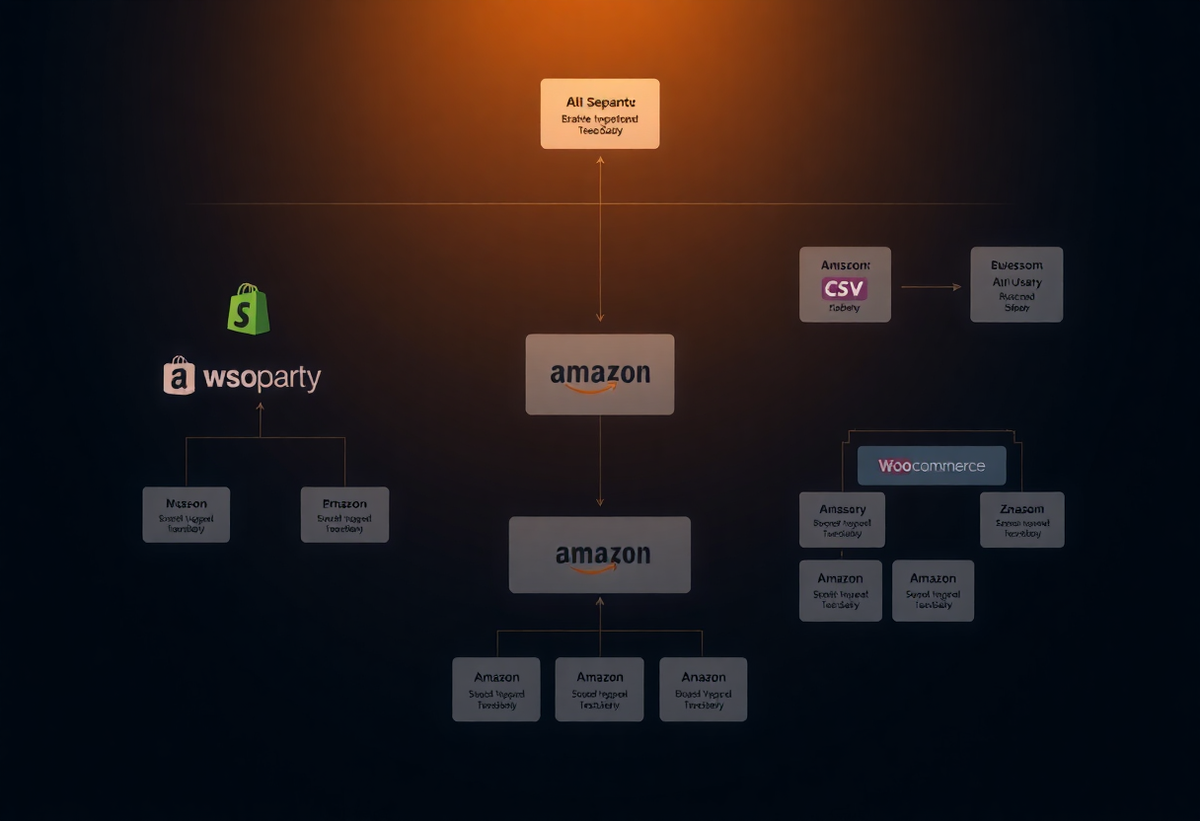
A 2023 JAMIA analysis of 12 health‑tech platforms found that proprietary connectors added an average of 9 months to deployment timelines and introduced a 14% error rate in cross‑vendor data alignment (JAMIA, 2023). ProtocolEngine’s approach replaces each vendor‑specific parser with a generic extractor that normalizes fields to a common ontology.

Figure 1 illustrates the data flow from source to normalized schema, highlighting the shared extraction layer and the validation step that flags missing attributes.
Schema Design for Vendor‑Agnosticism
The core schema defines 27 mandatory attributes, such as product_id, category, and compliance_code, and 15 optional extensions. By anchoring on a stable ontology, the engine can reference products from any source that supplies these fields, regardless of the underlying marketplace.
Uncertainty remains around long‑term support for emerging marketplace APIs; the consortium plans quarterly updates based on community pull requests.
Validation and Uncertainty in Cross‑Platform Data
To assess reliability, the engine incorporates a statistical validator that computes a concordance score between expected and observed attribute values; in the pilot, the median score was 0.88, indicating high alignment but leaving 12% of records requiring manual correction (ProtocolEngine, 2024). The evidence suggests that while the approach reduces integration time, the residual error must be managed through periodic audits.
Implementation Checklist
Key steps for teams building on the engine include: (1) define the mandatory attribute set; (2) map source fields to the ontology; (3) implement the extractor adapter for each marketplace; (4) configure the validator with threshold defaults; and (5) schedule quarterly schema reviews. Early deployments report an average of 3.2 person‑weeks from prototype to production, with a standard deviation of 0.9 weeks across five sites.



